Глава 14. Анализ данных и прогнозирование
14.1. Общая информация
Механизм анализа данных и прогнозирования позволяет реализовывать в прикладных решениях различные средства для выявления закономерностей, которые обычно скрываются за большими объемами информации.
Например, проанализировав данные о продажах товаров, можно выявить группы товаров, которые обычно покупаются вместе. В дальнейшем (один из многочисленных вариантов) эта информация может использоваться при раскладке товара в розничном магазине. Товары могут располагаться рядом (пришел покупатель за мангалом, увидел рядом жидкость для растопки, угли, мясо, удочки, резиновую лодку… в итоге купил все), могут располагаться в разных углах торгового зала (пришел покупатель за молоком, пока дойдет до хлеба, пройдет через весь магазин и еще чего-нибудь купит).
Другим примером использования механизма анализа данных является прогнозирование поведения контрагента, исходя из имеющихся данных о нем. Проведя такой анализ, можно выяснить, как зависит объем их закупок от территориального расположения, размера компании, времени сотрудничества и прочих показателей. На основании этих зависимостей можно спрогнозировать поведение нового контрагента и выбрать соответствующую стратегию для работы с ним.
Используя возможность построения прогнозов, можно планировать закупочную кампанию. Рассмотрим пример: в прошлом месяце зоомагазин продал 100 морских свинок. Нужно спланировать закупку товара на следующий месяц. Одним из вариантов (очень часто используемых) является ввод поправочного коэффициента на продажи прошлых периодов. Считаем, что поправочный коэффициент (коэффициент повышения спроса) равен 1,5. В итоге при планировании закупок описанным методом будем к следующему месяцу планировать закупку 150 морских свинок. Но если проанализировать, что обычно покупают клиенты после покупки таких питомцев, то можно прийти к совершенно другому выводу. Воспользовавшись возможностью проведения анализа данных, построения прогноза по этому анализу, можно прийти к выводу, что закупать на следующий месяц нужно корм, различные наполнители, сено и другие «аксессуары».
Следует отметить, что материал данной главы в первую очередь будет посвящен обзору механизмов «1С:Предприятия» и только косвенно будет касаться (на простых примерах) способов использования полученной информации.
14.2. Схема механизма
Общую схему работы механизма анализа и прогнозирования данных можно представить следующим образом:

Рис. 476. Схема взаимодействия элементов механизма анализа данных
Механизм позволяет работать как с данными, полученными из информационной базы, так и с данными, полученными из другого источника, предварительно загруженными в таблицу значений или табличный документ.
Применяя к исходным данным один из видов анализа, можно получить результат анализа. Результат анализа представляет собой некую модель поведения данных; может быть отображен в итоговом документе или сохранен для дальнейшего использования.
Дальнейшее использование результата анализа заключается в том, что на его основе может быть создана модель прогноза, позволяющая прогнозировать поведение новых данных в соответствии с имеющейся моделью.
Например, можно проанализировать, какие товары приобретаются вместе (в одной накладной), и сохранить созданную на основе данного анализа модель прогноза в базе данных. В дальнейшем при создании очередной накладной ранее сохраненную модель прогноза можно извлечь из информационной базы, подать ей на вход новые данные, содержащиеся в этой накладной, и на выходе получить прогноз ‑ список товаров, которые очередной клиент тоже приобретет (с определенной долей вероятности), если их ему предложить.
14.2.1. Основные объекты механизма
Схематично взаимосвязь основных объектов механизма анализа данных и
прогнозирования можно показать следующим образом:

Рис. 477. Взаимосвязь основных объектов
Анализ данных ‑ объект, непосредственно выполняющий анализ данных. Ему устанавливается источник данных, задаются параметры и исходные данные. Результатом работы данного объекта является результат анализа данных, причем для каждого типа анализа существует свой объект для работы с результатом анализа:
● РезультатАнализаДанныхОбщаяСтатистика,
● РезультатАнализаДанныхПоискАссоциаций,
● РезультатАнализаДанныхПоискПоследовательностей,
● РезультатАнализаДанныхДеревоРешений,
● РезультатАнализаДанныхКластеризация.
Настройка колонок анализа данных ‑ коллекция входных колонок анализа данных. Для каждой колонки указывается тип данных, содержащихся в ней, роль, выполняемая колонкой, дополнительные настройки, зависящие от типа производимого анализа.
Параметры анализа данных ‑ набор параметров производимого анализа данных. Состав параметров зависит от типа анализа. Например, для кластерного анализа указывается количество кластеров, на которые необходимо разбить исходные объекты, тип измерения расстояния между объектами и т. п.
Источник данных ‑ исходные данные для анализа. В качестве источника данных может выступать результат запроса, область ячеек табличного документа, таблица значений.
Результат анализа данных ‑ специальный объект, содержащий информацию о результате анализа. Для каждого вида анализа предусмотрен свой результат. Например, результатом анализа данных Дерево решений будет объект типа РезультатАнализаДанныхДеревоРешений. В дальнейшем результат может быть выведен в табличный документ при помощи построителя отчета анализа данных, может быть выведен посредством программного доступа к его содержимому, может быть использован для создания модели прогноза. Любой результат анализа данных может быть сохранен для последующего использования.
Модель прогноза ‑ специальный объект, позволяющий выполнять прогноз на основании входных данных (выборка для прогноза, настройки колонок выборки и результата, результат анализа). Тип модели прогноза зависит от типа результата анализа данных. Например, модель, созданная для типа анализа Поиск ассоциаций, будет иметь тип МодельПрогнозаПоискАссоциаций. Такая модель сможет выдавать прогнозы типа: т. к. данный покупатель купил заданный набор товаров, то с определенной вероятностью он должен купить и другой набор товаров. На вход модели прогноза передается источник данных для прогноза. Результатом является таблица значений, содержащая прогнозируемые значения.
Настройка входных колонок ‑ набор специальных объектов, показывающих соответствие между колонками модели прогноза и колонками выборки прогноза. Например, колонке модели прогноза с именем Товар может соответствовать колонка выборки Номенклатура.
Настройка колонок результата ‑ позволяет управлять тем, какие колонки будут помещены в результирующую таблицу модели прогноза. Например, для поиска ассоциаций можно вывести в результат номенклатуру, которую, скорее всего, приобретет клиент, и вероятность подобной покупки.
Колонки результата ‑ таблица значений, состоящая из колонок, указанных в настройках результирующих колонок, и содержащая прогнозируемые данные. Конкретное содержимое определяется типом анализа.
14.2.2. Типы анализа данных
В механизме анализа данных и прогнозирования реализовано несколько типов анализа данных:
● общая статистика,
● поиск ассоциаций,
● поиск последовательностей,
● кластерный анализ,
● дерево решений.
14.2.2.1. Общая статистика
Тип анализа Общая статистика представляет собой механизм для сбора общей информации о данных, находящихся в полученном источнике данных. Этот тип анализа предназначен для предварительного исследования анализируемой информации.
Анализ показывает ряд характеристик дискретных и непрерывных полей. При выводе отчета в табличный документ заполняются круговые диаграммы для отображения состава полей.
14.2.2.2. Поиск ассоциаций
Данный тип анализа осуществляет поиск часто встречаемых вместе групп объектов или значений характеристик, а также производит поиск правил ассоциаций. Поиск ассоциаций может использоваться, например, для определения часто приобретаемых вместе товаров или услуг.
Этот тип анализа может работать с иерархическими данными, что позволяет, например, находить правила не только для конкретных товаров, но и для их групп. Важной особенностью этого типа анализа является возможность работать как с объектным источником данных, в котором каждая колонка содержит некоторую характеристику объекта, так и с событийным источником, где характеристики объекта располагаются в одной колонке.
14.2.2.3. Поиск последовательностей
Тип анализа Поиск последовательностей позволяет выявлять в источнике данных последовательные цепочки событий. Например, это может быть цепочка товаров или услуг, которые часто последовательно приобретают клиенты.
Этот тип анализа позволяет осуществлять поиск по иерархии, что дает возможность отслеживать не только последовательности конкретных событий, но и последовательности родительских групп.
14.2.2.4. Кластерный анализ
Кластерный анализ позволяет разделить исходный набор исследуемых объектов на группы объектов таким образом, чтобы каждый объект был более схож с объектами из своей группы, чем с объектами других групп. Анализируя в дальнейшем полученные группы, называемые кластерами, можно определить, чем характеризуется та или иная группа, принять решение о методах работы с объектами различных групп. Например, при помощи кластерного анализа можно разделить клиентов, с которыми работает компания, на группы, для того, чтобы применять различные стратегии при работе с ними.
При помощи параметров кластерного анализа пользователь может настроить алгоритм, по которому будет производиться разбиение, а также может динамически изменять состав характеристик, учитываемых при анализе, настраивать для них весовые коэффициенты.
Результат кластеризации может быть выведен в дендрограмму ‑ специальный вид диаграммы, предназначенный для графического отображения результатов кластерного анализа.
14.2.2.5. Дерево решений
Тип анализа Дерево решений позволяет построить иерархическую структуру классифицирующих правил, представленную в виде дерева.
Для построения дерева решений необходимо выбрать целевой атрибут, по которому будет строиться классификатор, и ряд входных атрибутов, которые будут использоваться для создания правил. Целевой атрибут может содержать, например, информацию о том, перешел ли клиент к другому поставщику услуг, удачна ли была сделка, качественно ли была выполнена работа и т. д. Входными атрибутами, например, могут выступать возраст сотрудника, стаж его работы, материальное состояние клиента, количество сотрудников в компании и т. п.
Результат работы анализа представляется в виде дерева, каждый узел которого содержит некоторое условие. Для принятия решения, к какому классу следует отнести некий новый объект, необходимо, отвечая на вопросы в узлах, пройти цепочку от корня до листа дерева, переходя к дочерним узлам в случае утвердительного ответа и к соседнему узлу ‑ в случае отрицательного.
Набор параметров анализа позволяет регулировать точность полученного дерева.
14.2.3. Модели прогноза
Модели прогноза, создаваемые механизмом, представляют собой специальные объекты, которые создаются из результата анализа данных и позволяют в дальнейшем автоматически выполнять прогноз для новых данных.
Например, модель прогноза поиска ассоциаций, построенная при анализе покупок клиентов, может быть использована при работе с осуществляющим покупку клиентом, для того чтобы предложить ему товары, которые он с определенной степенью вероятности приобретет вместе с выбранными им товарами.
14.3. Тип анализа «Общая статистика»
Тип анализа Общая статистика может использоваться для предварительного анализа данных (перед выполнением другого вида анализа) и т. п.
В качестве источника данных, которые будут подвергаться анализу, может использоваться результат запроса, таблица значений или область ячеек табличного документа.
Данные в источнике (с точки зрения проводимого анализа) могут иметь непрерывный или дискретный вид. К непрерывным относятся такие типы, как Число, Дата. Остальные типы относятся к дискретным.
Для колонок разных видов предусмотрено получение различной информации.
Дискретные данные:
● Количество значений ‑ количество значений, встреченных в колонке источника данных (NULL значением не считается);
● Количество уникальных значений (с исключением повторяющихся значений);
● Мода ‑ значение, которое в источнике данных встречается наиболее часто. Если в данных несколько значений, встречаемых с одинаковой частотой, в качестве моды берется первое найденное;
● Частота ‑ количество вхождений значения в выборку данных;
● Относительная частота ‑ определяется как отношение количества вхождения значения к общему количеству значений;
● Накопленная частота ‑ считается как сумма частоты значения и сумма частот предыдущих значений выборки данных;
● Накопленная относительная частота ‑ считается как сумма накопленной частоты значения и сумма относительных частот предыдущих значений.
Непрерывные данные:
● Количество значений;
● Минимум значения;
● Максимум значения;
● Среднее;
● Размах ‑ разность между максимальным и минимальным значениями;
● Стандартное отклонение (среднеквадратичное отклонение);
● Медиана ‑ значение, лежащее в середине выборки.
Следует отметить, что если анализируется одновременно несколько полей различных видов, их анализ проводится вне зависимости друг от друга (исключается взаимная корреляция).
Рассмотрим указанные характеристики на примере.
Выборка данных (источник анализа) имеет следующее наполнение:
|
Номенклатура |
Количество |
|
Стол кухонный раскладной |
1 |
|
Табурет круглый |
2 |
|
Диван «УЮТ» |
1 |
|
Диван «Джинс» |
1 |
|
Кресло «Джинс» |
2 |
|
Стол «Kitchen» 0.9x1.7 |
1 |
|
Диван «Комфорт» |
1 |
|
Стол «Kitchen» 0.9x1.7 |
1 |
|
Стул «Summer» |
4 |
|
Диван «УЮТ» |
1 |
|
Стол кухонный раскладной |
1 |
|
Табурет прямоугольный |
3 |
|
Кресло «УЮТ» |
2 |
|
Кресло «УЮТ» |
2 |
|
Шкаф «Wardrobe» |
1 |
|
Стол кухонный раскладной |
1 |
|
Табурет прямоугольный |
2 |
|
Стол обеденный |
1 |
|
Стул «Summer» |
2 |
|
Табурет круглый |
2 |
В результате анализа данных для поля Количество (вид данных анализа Непрерывные) будут рассчитаны следующие характеристики:
|
Характеристика |
Значение |
|
Значений |
20 |
|
Минимум |
1 |
|
Максимум |
4 |
|
Среднее |
1,6 |
|
Размах |
3 |
|
Стандартное отклонение |
0,8208 |
|
Медиана |
1 |
Для поля Номенклатура будут получены следующие характеристики:
|
Характеристика |
Значение |
|
Количество значений |
20 |
|
Количество уникальных значений |
12 |
|
Мода |
Стол кухонный раскладной |
Таблица частот для значений номенклатуры будет иметь следующий вид:
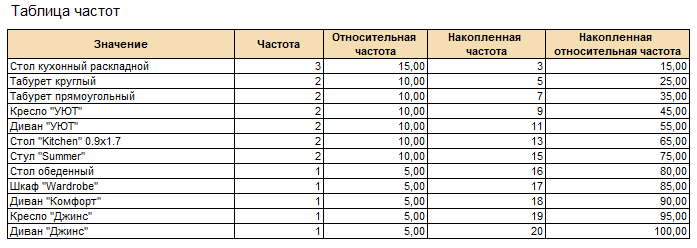
Рис. 478. Таблица частот
Относительная частота в виде диаграммы представлена далее:

Рис. 479. Диаграмма частот
Для выполнения данного анализа может использоваться фрагмент кода, аналогичный приведенному:
Копировать в буфер обмена&НаКлиенте Процедура ОбщаяСтатистика(Команда) Результат = АнализОбщаяСтатистика(); КонецПроцедуры &НаСервереБезКонтекста Функция АнализОбщаяСтатистика() Анализ = Новый АнализДанных; Анализ.ТипАнализа = Тип("АнализДанныхОбщаяСтатистика"); Запрос = Новый Запрос; Запрос.Текст = " |ВЫБРАТЬ |Продажи.Номенклатура, |Продажи.Количество |ИЗ |РегистрНакопления.Продажи КАК Продажи"; Анализ.ИсточникДанных = Запрос.Выполнить(); РезультатАнализа = Анализ.Выполнить(); Построитель = Новый ПостроительОтчетаАнализаДанных(); Построитель.Макет = Неопределено; Построитель.ТипАнализа = Тип("АнализДанныхОбщаяСтатистика"); ТабДок = Новый ТабличныйДокумент; Построитель.Вывести(РезультатАнализа, ТабДок); Возврат ТабДок; КонецФункции
Работа по проведению анализа данных выполняется в серверной внеконтекстной функции, которая возвращает на клиента табличный документ с результатами анализа. Сначала создается сам объект АнализДанных. После этого производится выбор типа проводимого анализа.
Далее по тексту определяется запрос. Результат запроса устанавливается как источник данных анализа. Сам анализ выполняется в процессе работы метода Выполнить() объекта АнализДанных.
Сам анализ не имеет средств по визуализации результата полученного анализа. Для этой цели используется объект ПостроительОтчетаАнализаДанных. При создании данного объекта повторно указывается тип проводимого анализа. Далее в качестве первого параметра метода Вывести() передается результат полученного анализа, вторым параметром передается ранее созданный объект ТабличныйДокумент.
В конце алгоритма табличный документ с результатом анализа возвращается на клиента в реквизит обработки Результат, имеющий тип ТабличныйДокумент.
В результате будут получены данные, аналогичные рассмотренным выше.
14.4. Тип анализа «Поиск ассоциаций»
Как уже было сказано ранее, данный тип анализа осуществляет поиск часто встречаемых вместе комбинаций объектов или значений характеристик. С его помощью можно определять группы одновременно закупаемых товаров, выявлять наиболее привлекательные источники информации (в процессе «оптимизации» затрат на них) и т. п.
Схематично процесс проведения анализа Поиск ассоциаций можно представить следующим образом:

Рис. 480. Схема выполнения анализа «Поиск ассоциаций»
В качестве источника данных может использоваться результат запроса, таблица значений или область ячеек табличного документа. С точки зрения данного типа анализа колонки источника можно разделить на следующие:
● НеИспользуемая ‑ игнорируются анализом;
● Объект ‑ данные из этой колонки используются как объекты (или события) проводимого анализа. Исходя из значения данной колонки, значения другой колонки (Элемент) относятся к одной ассоциируемой группе;
● Элемент ‑ данные из этой колонки используются для получения устойчивых групп значений, построения ассоциативных правил.
Кроме настройки типов колонок, на результат проводимого анализа влияют следующие параметры анализа:
● МинимальныйПроцентСлучаев ‑ определяется минимальный процент случаев, в которых должна встречаться комбинация элементов. Группы, у которых данное значение меньше указанного, не попадают в результат анализа;
● МинимальнаяДостоверность ‑ показывает минимальное значение процента случаев, когда правило соблюдается;
● МинимальнаяЗначимость ‑ группы, у которых данное значение меньше указанного, не попадают в результат анализа;
● ТипОтсеченияПравил ‑ один из вариантов системного перечисления ТипОтсеченияПравилАссоциации:
● Избыточные ‑ отсекать избыточные правила,
● Покрытые ‑ отсекать правила, покрытые другими правилами.
В результате выполнения анализа получаем:
● информацию о данных (количество объектов, количество элементов, среднее количество элементов в объекте, количество найденных групп, количество найденных правил ассоциаций);
● найденные группы элементов ‑ указывается состав группы, количество случаев, процент случаев, в которых эта группа встречается;
● найденные ассоциативные правила ‑ указывается исходный состав элементов, следствие (состав элементов), процент случаев, достоверность, значимость правила.
Рассмотрим особенности проведения данного типа анализа на следующей выборке данных (постараемся определить состав одновременно закупаемых товаров):
|
Регистратор |
Номенклатура |
|
Расходная накладная № 000000001 |
Стол кухонный раскладной |
|
Табурет круглый |
|
|
Расходная накладная № 000000002 |
Диван «УЮТ» |
|
Расходная накладная № 000000003 |
Диван «Джинс» |
|
Кресло «Джинс» |
|
|
Расходная накладная № 000000005 |
Стол «Kitchen» 0.9x1.7 |
|
Диван «Комфорт» |
|
|
Расходная накладная № 000000004 |
Стол «Kitchen» 0.9x1.7 |
|
Стул «Summer» |
|
|
Диван «УЮТ» |
|
|
Расходная накладная № 000000006 |
Стол кухонный раскладной |
|
Табурет прямоугольный |
|
|
Расходная накладная № 000000007 |
Кресло «УЮТ» |
|
Расходная накладная № 000000008 |
Кресло «УЮТ» |
|
Расходная накладная № 000000009 |
Шкаф «Wardrobe» |
|
Расходная накладная № 000000010 |
Стол кухонный раскладной |
|
Табурет прямоугольный |
|
|
Стол обеденный |
|
|
Расходная накладная № 000000011 |
Стул «Summer» |
|
Табурет круглый |
Признаком, по которому данные относятся к одной группе, будем считать значение регистратора (номенклатура, указанная в одном документе, считается закупленной одновременно). То есть Регистратор будет объектом анализа, Номенклатура ‑ элементом.
Для проведения анализа будем использовать следующий фрагмент кода:
Копировать в буфер обмена&НаКлиенте Процедура ПоискАссоциаций(Команда) Результат = АнализПоискАссоциаций(); КонецПроцедуры &НаСервереБезКонтекста Функция АнализПоискАссоциаций() Анализ = Новый АнализДанных; Анализ.ТипАнализа = Тип("АнализДанныхПоискАссоциаций"); Запрос = Новый Запрос; Запрос.Текст = " |ВЫБРАТЬ |Продажи.Регистратор, |Продажи.Номенклатура |ИЗ |РегистрНакопления.Продажи КАК Продажи"; Анализ.ИсточникДанных = Запрос.Выполнить(); // Строка приводится в качестве примера, // такое значение типа колонки по умолчанию. Анализ.НастройкаКолонок.Номенклатура.ТипКолонки = ТипКолонкиАнализаДанныхПоискАссоциаций.Элемент; // Строка приводится в качестве примера, // такое значение типа отсечения по умолчанию. Анализ.Параметры.ТипОтсеченияПравил.Значение = ТипОтсеченияПравилАссоциации.Избыточные; РезультатАнализа = Анализ.Выполнить(); Построитель = Новый ПостроительОтчетаАнализаДанных(); Построитель.Макет = Неопределено; Построитель.ТипАнализа = Тип("АнализДанныхПоискАссоциаций"); ТабДок = Новый ТабличныйДокумент; Построитель.Вывести(РезультатАнализа, ТабДок); Возврат ТабДок; КонецФункции
Результат анализа будет выглядеть следующим образом:

Рис. 481. Результат анализа «Поиск ассоциаций»
В выборе используются данные из одиннадцати документов (ссылка содержится в поле Регистратор), количество различных номенклатурных позиций равно двенадцати:
|
Номенклатура |
|
Стол кухонный раскладной |
|
Табурет круглый |
|
Диван «УЮТ» |
|
Диван «Джинс» |
|
Кресло «Джинс» |
|
Стол «Kitchen» 0.9x1.7 |
|
Диван «Комфорт» |
|
Стул «Summer» |
|
Табурет прямоугольный |
|
Кресло «УЮТ» |
|
Шкаф «Wardrobe» |
|
Стол обеденный |
Найдена следующая группа товаров:

Рис. 482. Найденная группа товаров
Вся группа встречается в документе только в двух случаях из одиннадцати (это и показано в колонках Количество случаев и Процент случаев).
Получены следующие ассоциативные правила:

Рис. 483. Ассоциативные правила
Разберем второе из них. В двух случаях из одиннадцати в документе вместе с позицией Стол кухонный раскладной встречалась позиция Табурет прямоугольный. Исходя из этого, был рассчитан процент случаев: (2 / 11 * 100 = 18,18 %).
Достоверность была рассчитана следующим образом: обе номенклатурные позиции закупались в двух случаях, товарная позиция Стол кухонный раскладной встречалась в покупках 3 раза. Исходя из этого, достоверность равна: 2 / 3 * 100 = 66,67 %.
Значимость определяется как отношение достоверности правила к проценту нахождения Табурет прямоугольный в закупаемых товарах. Эта позиция встречается в двух документах из одиннадцати (18,18 %). Значимость равна: 66,67 % / 18,18 % = 3,67.
14.4.1. Типы отсечения правил
Рассмотрим такой важный параметр данного типа анализа, как ТипОтсеченияПравил. Возможные значения отсечения содержатся в системном перечислении ТипОтсеченияПравилАссоциации, их состав:
● Покрытые,
● Избыточные.
Перед тем как перейти к рассмотрению особенностей вариантов отсечения, рассмотрим несколько общих моментов, применимых к правилам ассоциации.
Любое правило состоит из предпосылки и следствия. Например:
● Предпосылка: Если купили Товар № 1.
● Следствие: То купят Товар № 2.
При этом не нужно забывать, что следствие наступает с определенной достоверностью. При отсечении правил вероятностные характеристики могут рассматриваться, а могут и игнорироваться (важно только содержание правила).
14.4.1.1. Отсечение покрытых правил
Рассмотрим вариант отсечения Покрытые.
Правило может быть покрыто как по предпосылке, так и по следствию. Например:
● Правило № 1: Если купили товар № 1 и № 3, То купят товар № 2.
● Правило № 2: Если купили товар № 1, То купят товар № 2.
В этом случае правило № 1 будет считаться покрытым, т. к. предпосылка первого правила получается «избыточной» по отношению к предпосылке второго правила.
Пример покрытия по следствию:
● Правило № 1: Если купили товар № 1, То купят товар № 2, № 3.
● Правило № 2: Если купили товар № 1, То купят товар № 3.
Правило № 2 будет покрыто по следствию, так как следствие правила № 1 более полное.
14.4.1.2. Отсечение избыточных правил
Покрытие не учитывает вероятностных характеристик правил, они учитываются в случае, если используется вариант отсечения Избыточные.
Правило будет считаться избыточным по предпосылке, если оно покрыто по предпосылке и его достоверность равна достоверности покрывающего правила. Например:
● Правило № 1: Если купили товар № 1 и № 3, То купят товар № 2 с достоверностью 75 %.
● Правило № 2 Если купили товар № 1, То купят товар № 2 с достоверностью 75 %.
Правило № 1 избыточно по отношению к правилу № 2 (оно содержит дополнительное условие, не вносящее «возмущения» в вероятностные характеристики правила).
Правило № 1 будет считаться избыточным по следствию, если количество случаев данного правила равно количеству случаев покрывающего правила.
● Правило № 1: Если купили товар № 1, То купят товар № 2, № 3 в трех случаях.
● Правило № 2: Если купили товар № 1, То купят товар № 3 в трех случаях.
Правило № 2 будет считаться избыточным по отношению к правилу № 1, так как оно содержит более простое следствие с теми же вероятностными характеристиками.
14.5. Тип анализа «Поиск последовательностей»
Данный тип анализа позволяет выявить цепочки возникающих событий (шаблоны последовательностей). Он может использоваться тогда, когда одним из важных анализируемых показателей является последовательность наступления событий во времени. Например, можно выявить последовательность товаров, которые закупаются друг за другом в течение какого-либо определенного промежутка времени и т. п.
Схематично процесс проведения анализа Поиск последовательностей можно представить следующим образом:

Рис. 484. Схема выполнения анализа «Поиск последовательностей»
В качестве источника данных может использоваться результат запроса, таблица значений, область ячеек табличного документа. С точки зрения данного типа анализа колонки источника можно разделить на следующие:
● НеИспользуемая ‑ игнорируются анализом;
● Последовательность ‑ данные из этой колонки используются для анализа как объект события последовательности. По значению данной колонки анализ и ассоциирует данные с одной цепочкой событий;
● Элемент ‑ данные из этой колонки используются как элементы последовательности;
● Время ‑ именно по данной колонке определяется время наступления события. Наличие данной колонки обязательно при проведении данного типа анализа.
Кроме настройки типов колонок, на результат проводимого анализа влияют следующие параметры анализа:
● МинимальныйПроцентСлучаев ‑ минимальный процент последовательностей, в которых наблюдается найденный шаблон последовательности;
● МинимальныйИнтервал ‑ признак установки минимального интервала последовательности (должна быть установлена единица измерения интервала, кратность);
● МаксимальныйИнтервал ‑ признак установки максимального интервала последовательности (должна быть установлена единица измерения интервала, кратность);
● ИнтервалЭквивалентностиВремени ‑ признак установки интервала эквивалентности времени (должна быть установлена единица интервала эквивалентности времени, ее кратность);
● МинимальнаяДлина ‑ минимальная длина искомых последовательностей;
● ПоискПоИерархии ‑ признак осуществления поиска по иерархии (распространяется на колонки с типом Элемент).
Ряд свойств оперирует таким понятием, как ТипЕдиницыИнтервалаВремениАнализаДанных. Данное системное перечисление содержит следующие значения:
|
Секунда |
|
|
Минута |
ТекущаяМинута |
|
Час |
ТекущийЧас |
|
День |
ТекущийДень |
|
Неделя |
ТекущаяНеделя |
|
Декада |
ТекущаяДекада |
|
Месяц |
ТекущийМесяц |
|
Квартал |
ТекущийКвартал |
|
Полугодие |
ТекущееПолугодие |
|
Год |
ТекущийГод |
Основным результатом анализа являются найденные шаблоны последовательностей. Эти шаблоны содержат следующую информацию:
● состав шаблона последовательности;
● количество случаев, в которых наблюдалась данная последовательность;
● максимальные интервалы между событиями (в случае, если событий 2, то интервал один);
● минимальные интервалы между событиями (в случае, если событий 2, то интервал один);
● процент случаев, когда данная последовательность выполнилась;
● средние интервалы между событиями (в случае, если событий 2, то интервал один).
Особенности выполнения данного типа анализа рассмотрим на примере следующей выборки данных:
|
Контрагент |
Первая покупка |
Вторая покупка |
Третья покупка |
Интервал |
|
Бондарев В.И. |
Стол кухонный раскладной |
Диван «УЮТ» |
Кресло «УЮТ» |
25 дней, 31 день |
|
Табурет круглый |
||||
|
Иванов И.П. |
Диван «Джинс» |
|
|
|
|
Кресло «Джинс» |
||||
|
Петров Б.С. |
Стол «Kitchen» 0.9x1.7 |
Кресло «УЮТ»
|
|
43 дня |
|
Стул «Summer» |
||||
|
Диван «УЮТ» |
||||
|
Сидоров Г.О. |
Стол кухонный раскладной |
|
|
|
|
Табурет прямоугольный |
||||
|
Степанов В.К. |
Стол кухонный раскладной |
|
|
|
|
Табурет прямоугольный |
||||
|
Стол обеденный |
||||
|
Федоров Д.Е. |
Стол «Kitchen» 0.9x1.7 |
Шкаф «Wardrobe» |
Стул «Summer» |
58 дней, 29 дней |
|
Диван «Комфорт» |
Табурет круглый |
Данные из колонки Контрагент будут определять принадлежность к конкретной цепочке событий, т. е. они определяют последовательность анализа. Номенклатура будет являться элементом получаемой последовательности.
Для проведения анализа может использоваться фрагмент кода, аналогичный приведенному ниже:
Копировать в буфер обмена&НаКлиенте Процедура ПоискПоследовательностей(Команда) Результат = АнализПоискПоследовательностей(); КонецПроцедуры &НаСервереБезКонтекста Функция АнализПоискПоследовательностей() Анализ = Новый АнализДанных; Анализ.ТипАнализа = Тип("АнализДанныхПоискПоследовательностей"); Запрос = Новый Запрос; Запрос.Текст = " |ВЫБРАТЬ |Продажи.Контрагент, |Продажи.Номенклатура, |Продажи.Период |ИЗ |РегистрНакопления.Продажи КАК Продажи"; Анализ.ИсточникДанных = Запрос.Выполнить(); Анализ.НастройкаКолонок.Период.ТипКолонки = ТипКолонкиАнализаДанныхПоискПоследовательностей.Время; РезультатАнализа = Анализ.Выполнить(); Построитель = Новый ПостроительОтчетаАнализаДанных(); Построитель.Макет = Неопределено; Построитель.ТипАнализа = Тип("АнализДанныхПоискПоследовательностей"); ТабДок = Новый ТабличныйДокумент; Построитель.Вывести(РезультатАнализа, ТабДок); Возврат ТабДок; КонецФункции
Поле Период определяется как Время непосредственно из кода (самостоятельно анализом не определяется).
Параметры анализа, установленные по умолчанию:

Рис. 485. Параметры анализа
После проведения анализа получены следующие общие данные:

Рис. 486. Общие данные анализа
Количество элементов равно двенадцати. Ровно столько номенклатурных позиций встречается в приведенной выборке данных.
Найдены две последовательности:

Рис. 487. Найденные последовательности
Первая последовательность встречается в двух случаях из пяти. Исходя из этого, процент случаев равен 40 %. Так как глубина последовательности равна 2, существует по одному значению каждого из приводимых интервалов.
14.6. Тип анализа «Дерево решений»
С помощью данного типа анализа можно получить причинно-следственную иерархию условий, приводящую к определенному решению. Например, получить дерево условий, по которому (с определенной долей вероятности) можно понять причину расторжения договоров с клиентами компании, определения условий, влияющих на вариант заключаемого договора. Можно проводить «профилирование» менеджеров компании по различным видам ее клиентов и т. п.
Схематично процесс проведения анализа Дерево решений можно представить следующим образом:

Рис. 488. Схема выполнения анализа «Дерево решений»
С точки зрения данного типа анализа колонки источника можно разделить на следующие:
● НеИспользуемая,
● Входная,
● Прогнозируемая.
Используемые параметры анализа:
● МинимальноеКоличествоСлучаев ‑ минимальное количество элементов в узле;
● МаксимальнаяГлубина ‑ максимальная глубина дерева;
● ТипУпрощения ‑ тип упрощения дерева решений.
В результате проведенного анализа можно получить:
● дерево решений,
● ошибки классификации.
Разберемся с особенностью данного типа анализа на примере следующей выборки данных:
|
Контрагент |
Количество розничных точек |
Количество автомобилей |
Время работы организации |
Время заключения договора |
Вид договора |
Состояние взаимоотношений |
|
ЗАО Игорь |
1 |
0 |
Меньше года |
Меньше года |
Дилер |
Несоблюдение договора |
|
ЗАО ТогрМебель |
15 |
4 |
От трех до десяти лет |
Меньше года |
Дистрибьютор |
Прекращение контрагентом |
|
ЗАО ТогрМебель |
1 |
10 |
От трех до десяти лет |
От года до трех |
Дистрибьютор |
Прекращение контрагентом |
|
ИЧП Дубрава |
1 |
1 |
От года до трех |
Меньше года |
Дилер |
Прекращение контрагентом |
|
Магазин № 15 |
1 |
1 |
Свыше десяти лет |
От трех до десяти лет |
Постоянный партнер |
Не прекращены |
|
ООО Гросс |
3 |
2 |
Меньше года |
Меньше года |
Постоянный партнер |
Не прекращены |
|
ООО Интарис |
7 |
3 |
От трех до десяти лет |
От года до трех |
Постоянный партнер |
Прекращение контрагентом |
|
ООО ТогрТрест |
2 |
2 |
Свыше десяти лет |
От трех до десяти лет |
Постоянный партнер |
Не прекращены |
|
ПБОЮЛ Курочкин |
0 |
1 |
Меньше года |
Меньше года |
Дилер |
Не прекращены |
Для проведения анализа может использоваться фрагмент кода, аналогичный приведенному ниже:
Копировать в буфер обмена&НаКлиенте Процедура ДеревоРешений(Команда) Результат = АнализДеревоРешений(); КонецПроцедуры &НаСервереБезКонтекста Функция АнализДеревоРешений() Анализ = Новый АнализДанных; Анализ.ТипАнализа = Тип("АнализДанныхДеревоРешений"); Группа = Справочники.Контрагенты.НайтиПоНаименованию("Юридические лица"); Запрос = Новый Запрос; Запрос.Текст = " |ВЫБРАТЬ |Контрагенты.Ссылка, |Контрагенты.КоличествоРозничныхТочек, |Контрагенты.КоличествоАвтомобилей, |Контрагенты.ВремяРаботыОрганизации, |Контрагенты.ВремяЗаключенияДоговора, |Контрагенты.ВидДоговора, |Контрагенты.ПрекращениеОтношений |ИЗ |Справочник.Контрагенты КАК Контрагенты |ГДЕ |(Не Контрагенты.ЭтоГруппа И Контрагенты.Родитель = &Родитель)"; Запрос.УстановитьПараметр("Родитель", Группа); Анализ.ИсточникДанных = Запрос.Выполнить(); Анализ.Параметры.ТипУпрощения.Значение = ТипУпрощенияДереваРешений.НеУпрощать; РезультатАнализа = Анализ.Выполнить(); Построитель = Новый ПостроительОтчетаАнализаДанных(); Построитель.Макет = Неопределено; Построитель.ТипАнализа = Тип("АнализДанныхДеревоРешений"); ТабДок = Новый ТабличныйДокумент; Построитель.Вывести(РезультатАнализа, ТабДок); Возврат ТабДок; КонецФункции
В результате проведения анализа получено следующее дерево решений:
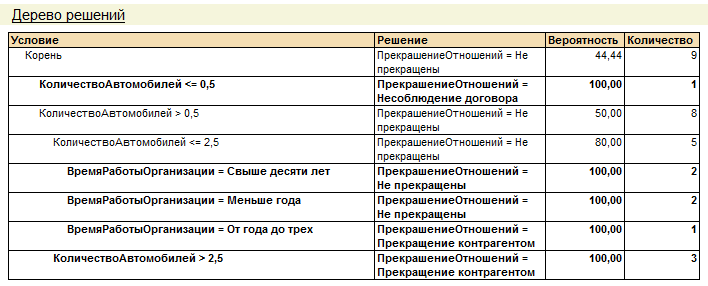
Рис. 489. Дерево решений
Данное дерево можно представить в виде следующей схемы:
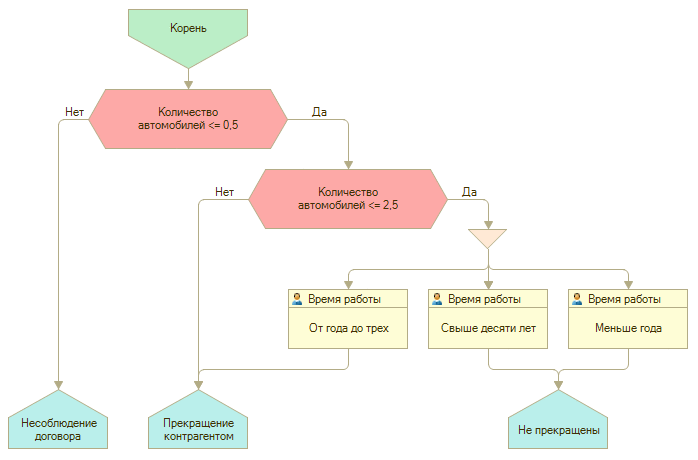
Рис. 490. Представление дерева решения в виде схемы
Ошибки классификации показывают, в каких случаях полученные правила расходятся с действительностью (исходной выборкой данных):

Рис. 491. Ошибки классификации
Исходя из приведенных данных, видно, что ошибок в полученной классификации нет, то есть данные в фактической выборке совпадают с данными классификации.
Предыдущий пример получен, исходя из значения НеУпрощать параметра анализа ТипУпрощения. Данное значение параметра задано программно в примере выше. Если установить значение Упрощать параметра, дерево решений примет такой вид:

Рис. 492. Дерево решений
Упрощение дерева заключается в том, что по определенным правилам (формулам, которые будут рассмотрены ниже) узлы дерева превращаются в листья (отсекается лишнее ветвление).
При принятии решения о том, будет ли произведено преобразование узла в лист, учитываются следующие показатели:
● Ошибок ‑ количество ошибок в узле;
● ОшибокДочерних ‑ количество ошибок в дочерних узлах;
● Листов ‑ количество листов в узле;
● Случаев ‑ количество случаев.

Решение о превращении узла в лист принимается в случае выполнения условия:

В нашем примере для узлов Время работы организации условие выполняется (0,5 < 1).
В связи с использованием упрощений появились и ошибки в классификации, что показано в результате анализа:

Рис. 493. Ошибки классификации
Например, существует один случай, когда в реальной выборке данных было значение Прекращение контрагентом, а по полученной классификации должно быть значение Не прекращены и т. п.
14.7. Тип анализа «Кластеризация»
Кластерный анализ ‑ математическая процедура многомерного анализа, позволяющая на основе множества показателей, характеризующих ряд объектов, сгруппировать их в кластеры таким образом, чтобы объекты, входящие в один кластер, были более однородными, сходными, по сравнению с объектами, входящими в другие кластеры.
В основе данного анализа лежит вычисление расстояния между объектами. Именно исходя из расстояний между объектами и производится их группировка по кластерам. Определение расстояния может проводиться разными способами (по разным метрикам). Поддерживаются следующие метрики:
● Евклидова метрика,
● Евклидова метрика в квадрате,
● Метрика города,
● Метрика доминирования.
После определения расстояний между объектами может использоваться один из нескольких алгоритмов распределения объектов по кластерам. Поддерживаются следующие методы кластеризации:
● Ближняя связь,
● Дальняя связь,
● k-средних,
● Центр тяжести.
Схематично механизм проведения кластерного анализа можно представить следующим образом:

Рис. 494. Схема выполнения кластерного анализа
На вход объекту АнализДанных подается источник данных. В качестве источника может выступать результат запроса, таблица значений, область ячеек табличного документа. Колонки источника определяются как входные либо неиспользуемые. Следует отметить, что все значения колонок содержатся в системном перечислении ТипКолонкиАнализаДанныхКластеризация. В этом перечислении значений больше (не только неиспользуемые и входные), но другие значения используются при построении прогнозов.
Анализ производится в соответствии с установленными параметрами анализа.
В качестве примера, иллюстрирующего возможность проведения кластерного анализа, будем использовать следующий фрагмент кода:
Копировать в буфер обмена&НаКлиенте Процедура КластерныйАнализ(Команда) Результат = АнализКластеризация(); КонецПроцедуры &НаСервереБезКонтекста Функция АнализКластеризация() Анализ = Новый АнализДанных; Анализ.ТипАнализа = Тип("АнализДанныхКластеризация"); Группа = Справочники.Контрагенты.НайтиПоНаименованию("Юридические лица"); Запрос = Новый Запрос; Запрос.Текст = " |ВЫБРАТЬ |Контрагенты.Ссылка, |Контрагенты.КоличествоРозничныхТочек, |Контрагенты.КоличествоАвтомобилей, |Контрагенты.ВремяРаботыОрганизации, |Контрагенты.ВремяЗаключенияДоговора, |Контрагенты.ВидДоговора, |Контрагенты.ПрекращениеОтношений |ИЗ |Справочник.Контрагенты КАК Контрагенты |ГДЕ |(Не Контрагенты.ЭтоГруппа И Контрагенты.Родитель = &Родитель)"; Запрос.УстановитьПараметр("Родитель", Группа); Анализ.ИсточникДанных = Запрос.Выполнить(); // Выбор метрики. Анализ.Параметры.МераРасстояния.Значение = ТипМерыРасстоянияАнализаДанных.ЕвклидоваМетрикаВКвадрате; // Выбор метода кластеризации. Анализ.Параметры.МетодКластеризации.Значение = МетодКластеризации.КСредних; РезультатАнализа = Анализ.Выполнить(); Построитель = Новый ПостроительОтчетаАнализаДанных(); Построитель.Макет = Неопределено; Построитель.ТипАнализа = Тип("АнализДанныхКластеризация"); ТабДок = Новый ТабличныйДокумент; Построитель.Вывести(РезультатАнализа, ТабДок); Возврат ТабДок; КонецФункции
Запрос выполняется по справочнику Контрагенты. По условию запроса выбираются только детальные записи справочника из группы Юридические лица.
Выполнение указанного кода приведет к тому, что в качестве начальных установок анализа данных будут определены следующие значения (часть установлена явно, часть ‑ по умолчанию):

Рис. 495. Параметры анализа
Состав колонок определился, исходя из состава полей выборки запроса. По умолчанию они определены с равным весом. Для типов Число и Дата определен вид данных Непрерывные, для остальных типов ‑ Дискретные. При необходимости изменить параметры колонок это можно сделать по аналогии с приведенным фрагментом:
Копировать в буфер обменаАнализ.НастройкаКолонок.КоличествоАвтомобилей.ДополнительныеПараметры.Вес = 2;
В данной строке для колонки КоличествоАвтомобилей увеличен вес.
Выборка данных, для которых будет произведен анализ, имеет следующее наполнение:
|
Контрагент |
Количество розничных точек |
Количество автомобилей |
Время работы организации |
Время заключения договора |
Вид договора |
Состояние взаимоотношений |
|
ЗАО Игорь |
1 |
0 |
Меньше года |
Меньше года |
Дилер |
Несоблюдение договора |
|
ЗАО ТогрМебель |
15 |
4 |
От трех до десяти лет |
Меньше года |
Дистрибьютор |
Прекращение контрагентом |
|
ЗАО ТогрМебель |
1 |
10 |
От трех до десяти лет |
От года до трех |
Дистрибьютор |
Прекращение контрагентом |
|
ИЧП Дубрава |
1 |
1 |
От года до трех |
Меньше года |
Дилер |
Прекращение контрагентом |
|
Магазин № 15 |
1 |
1 |
Свыше десяти лет |
От трех до десяти лет |
Постоянный партнер |
Не прекращены |
|
ООО Гросс |
3 |
2 |
Меньше года |
Меньше года |
Постоянный партнер |
Не прекращены |
|
ООО Интарис |
7 |
3 |
От трех до десяти лет |
От года до трех |
Постоянный партнер |
Прекращение контрагентом |
|
ООО ТогрТрест |
2 |
2 |
Свыше десяти лет |
От трех до десяти лет |
Постоянный партнер |
Не прекращены |
|
ПБОЮЛ Курочкин |
0 |
1 |
Меньше года |
Меньше года |
Дилер |
Не прекращены |
Результат анализа будет получен в следующем виде:

Рис. 496. Результат кластерного анализа
Отметим тот факт, что в результате анализа получаются данные именно о найденных кластерах (их количество, центры, расстояния между ними). В результате анализа не получаются данные о том, какие объекты (в нашем случае контрагенты) в какие кластеры входят. Подобное поведение наблюдается в случае, если настройка параметров проводимого анализа не проводится явным образом (а именно параметра ТипЗаполненияТаблицы).
Для того чтобы в результате анализа увидеть распределение объектов по кластерам, необходимо перед выполнением анализа (но после определения его типа) определить следующую строку кода:
Копировать в буфер обменаАнализ.Параметры.ТипЗаполненияТаблицы.Значение = ТипЗаполненияТаблицыРезультатаАнализаДанных.ИспользуемыеПоля;
14.7.1. Используемые метрики
Сразу отметим такой факт: несмотря на то, что в предыдущем примере входные колонки имели непрерывный тип (для этого типа очевидно понятие «расстояния»), при анализе могут использоваться и колонки дискретных типов (ссылки на справочники, значения перечислений и т. п.).
Разберемся с метриками, которые могут использоваться при проведении кластерного анализа.
14.7.1.1. Евклидова метрика
В данной метрике расстояние между двумя объектами вычисляется по формуле:

Где:
● Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
● Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
● i ‑ номер атрибута, от 1 до n;
● n ‑ число атрибутов.
Предположим, что объекты характеризуются одним свойством, которое у одного объекта имеет значение 9, у другого ‑ 5. Весовой коэффициент данного атрибута равен единице. Расстояние между объектами будет равно:

14.7.1.2. Евклидова метрика в квадрате
В данной метрике расстояние между двумя объектами вычисляется по формуле:

Где:
● Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
● Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
● i ‑ номер атрибута, от 1 до n;
● n ‑ число атрибутов.
Предположим, что объекты характеризуются одним свойством, которое у одного объекта имеет значение 5, у другого ‑ 3. Весовой коэффициент данного атрибута равен двум. Расстояние между объектами будет равно:

14.7.1.3. Метрика города
В данной метрике расстояние между двумя объектами вычисляется по формуле:

Где:
● Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
● Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
● i ‑ номер атрибута, от 1 до n;
● n ‑ число атрибутов.
Предположим, что объекты характеризуются двумя атрибутами, которые имеют значения 3 и 5, 7 и 3. Вес первого равен 2, вес второго равен 1:

Рис. 497. Характеристики объектов
![]()
14.7.1.4. Метрика доминирования
В данной метрике расстояние между двумя объектами вычисляется по формуле:

Где:
● Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
● Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
● i ‑ номер атрибута, от 1 до n;
● n ‑ число атрибутов.
Предположим, что объекты характеризуются двумя атрибутами, которые имеют значения 3 и 5, 7 и 3. Вес первого равен 2, вес второго равен 1 (см. рис. 497).

14.7.2. Методы кластеризации
Вариант метода кластеризации определяет, исходя из каких принципов объект соотносится к той или иной группе, по какому алгоритму производится формирование кластеров.
Можно сказать, что целью любого алгоритма кластеризации является:
● минимизация изменчивости внутри кластеров,
● максимизация изменчивости между кластерами.
Различия между методами будем рассматривать на объектах, представленных на рисунке (см. рис. 498).
Будем считать, что объекты образуют две группы. Первая состоит из объектов 1, 2 и 3. Вторая группа состоит из объектов 4, 5 и 6.

14.7.2.1. Ближняя связь
Метод кластеризации, в котором объект присоединяется к той группе, для которой расстояние до ближайшего объекта минимально.
В рассматриваемом примере объект 7 будет включен в группу, в которой находится объект 4. Самыми близкими объектами двух групп являются объекты 4 и 3. Расстояние до объекта 4 минимально.
14.7.2.2. Дальняя связь
Метод кластеризации, в котором объект присоединяется к той группе, для которой расстояние до наиболее дальнего объекта минимально.
В рассматриваемом примере объект 7 будет включен в группу, в которой находится объект 5. Самыми дальними объектами двух групп являются объекты 1 и 5. Расстояние до объекта 5 меньше.
14.7.2.3. Центр тяжести
Метод кластеризации, в котором объект присоединяется к той группе, для которой расстояние до центра тяжести минимально:

Рис. 499. Группы объектов
В примере, рассмотренном на рисунке, объект 7 добавится в группу, содержащую объекты 4, 5 и 6. Расстояние до центра тяжести (некоего мифического объекта со средними значениями атрибутов) минимально.
14.7.2.4. k-средних
В данном методе выбираются объекты, находящиеся первыми в выборке. Они считаются центрами кластеров. Далее выбирается следующий объект и, в соответствии с расстоянием до центров кластеров, относится к тому или иному кластеру. Центр кластера, к которому был добавлен объект, пересчитывается.
Процедура повторяется до полного перебора всех объектов. Далее опять производится новая выборка объектов (начиная с первого). Процедура повторяется до тех пор, пока изменяются центры кластеров:

Рис. 500. Пример расположения объектов
Предположим, что произвольно выбраны в качестве центров кластеров объекты 1 и 2. Объект 3 добавляется к кластеру, центром которого является объект 1. Центр первого кластера перерассчитывается (он находится между объектом 1 и 3). Объект 4 добавляется ко второму кластеру (его центр также перерассчитывается).
После перебора всех анализируемых объектов к первому кластеру относятся объекты 1 и 3, ко второму ‑ остальные объекты (его центр предположительно находится в центре треугольника из объектов 4, 7, 6).
Далее опять производится выборка объектов и распределение их по кластерам (относительно постоянно рассчитываемых центров кластеров).
Где-то на третьей выборке объектов, скорее всего, объект 2, который изначально был центром второго кластера, станет относиться к первому кластеру.
В конце алгоритма к первому кластеру будут относиться объекты 1, 2, 3. Ко второму ‑ объекты 4, 5, 6, 7.
14.7.2.5. Вывод данных в дендрограмму
При выводе данных кластерного анализа, если используется алгоритм, отличный от алгоритма k-средних, результаты кластерного анализа выводятся в виде дендрограммы (алгоритм анализа должен предусматривать вывод распределения анализируемых объектов по кластерам):

Рис. 501. Дендрограмма